<twoyao>
Mongodb2018年放出公告(https://www.Mongodb.com/transactions),宣称将于今年夏天发布4.0版本,支持多文档事务
Mongodb 4.0 (available today as a Release Candidate) adds support for multi-document transactions, making it the only database to combine the speed, flexibility, and power of the document model with ACID guarantees. Through snapshot isolation, transactions provide a consistent view of data, and enforce all-or-nothing execution to maintain data integrity. Mongodb 4.0 will be Generally Available in Summer 2018.1
听到这个消息,内心有点小期待。总所周知,NoSQL数据库因其水平可扩展性受到广大开发者青睐,但是都没有提供多文档事务(multi-document transaction)支持,并非是多文档事务不重要,而是因为It’s too damn hard!涉及分布式的问题从不简单!

在分布式的环境下简单的问题将变得无比棘手。比如说,1) 计算机时钟是不可靠的,石英晶体谐振器存在误差,润1秒,ntp校准导致时间跳跃,甚至可能出现gettimeofday两次调用后者比前者还小的情况,所以即使2个进程收到同一个客户端的一条消息它们也不能各自根据自己的时钟判断出消息的全局顺序。你说你5点收到,但我不知你的5点是哪个时区(偏差值),虽然对客户端来说却是有明显的先后顺序。2) 网络也是不可靠的,进程A往进程B发了一条消息,但是没收到回应,可能是丢包,可能是B未及时响应,也可能是B挂了。但A没法知道,它只能怀疑B可能也许是挂了。3) 甚至连代码也不可靠,上行语句刚获取了时间,接着“马上”使用该时间进行某项操作,但你以为真的是“马上”?可能2行代码之间隔着一个Stop-the-world GC,中断一分钟这种情况也不是没出现过。即使是没有GC的语言也可能因为操作系统调度,手贱按了ctrl+z挂起进程…
正是因为这些问题导致事务在NoSQL中长期缺位,使得许多开发者谨慎地对待NoSQL数据库。当然也不是没有一些迂回手段,比如说Mongodb单文档的写操作是原子性的,如果业务模型中的对应关系是一对多,可以用嵌套文档来映射,将“多文档”的更新整合到一个写操作。或者使用two-phase commit,尽管我觉得这东西实在难以维护。又或者使用分布式锁限制find-and-modify的并发,我们在之前的项目中就用了redlock。Martin分析到redis的锁并不是strict correctness,他推荐用zookeeper来实现分布式锁。又或者干脆将一些需要事务支持的业务数据存储在支持事务的关系型数据库中。总的来说这些规避事务的方法都不轻松,只能覆盖到有限的应用场景。
数据库本就应该提供事务支持,NoSQL数据因为难以实现而不实现导致应用开发者不得不依靠各自漏洞百出的策略规避。但幸运的是,今天夏天将迎来转机,Mongodb将支持多文档事务(ACID)。现在已经可以在页面上申请Beta试用。我提交了申请,不过目前还未收到答复。但这并不影响我进行一些前瞻(扯淡)。首先看事务API的用法,与传统关系数据库类似
try (ClientSession clientSession = client.startSession()) {
clientSession.startTransaction();
try {
collection.insertOne(clientSession, docOne);
collection.insertOne(clientSession, docTwo);
clientSession.commitTransaction();
} catch (Exception e) {
clientSession.abortTransaction();
}
}看似简单的接口下是复杂的抽象。Mongodb为了实现多文档事务从3.0起就使用wiredTiger引擎替换旧的MMAPv1,并逐步实现多文档事务所必需的各种垫脚石。下面就谈谈这些“垫脚石”。

1. WiredTiger timestamps 高可用的系统需要多节点部署以便应付单一节点(准确地说是少于n/2)故障的问题。但多节点之间则又必须保持数据的一致性(consensus)。这个问题等价于total order broadcast。total order broadcast,简单来说就是保证,1) 每个节点都按相同的顺序接收消息。2) 每个节点都能接收到消息。这里说的消息比如说是Mongodb的oplog,主从节点以相同的顺序处理消息,假定没有新的请求那么最终所有节点最终都会到达相同的状态(eventual consistency)。Mongodb oplog的每个entry带有这么一个timestamp,记录了数据写入的时间。Journal中entry的发生顺序并非其在文件中的存储的顺序,因为在并行执行多个写入操作时有可能有些先发生的操作却是后写入文件。而有了这个timestmap就能比较entries的发生顺序。这个timestamp也并非真正意义“时间戳”,只是逻辑上先后的一个64bit的数字。前文已经提到分布式的节点没法统一真正的时间。
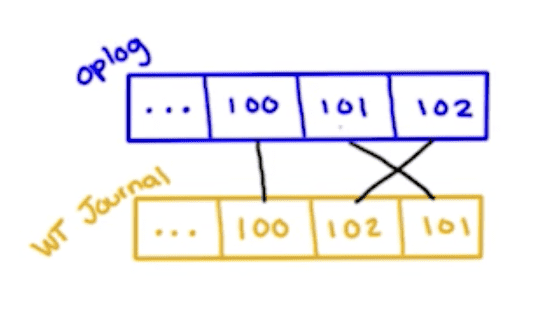
Timestamp给予了mongo记录事件先后顺序的能力。这在很多方面起到重要作用。试想一个场景,假设主节点的oplog为[1, 2, 3, 4, 5, 6],其中1, 2, 3已经同步到其他从节点(只需半数从节点达成),而4,5,6则还未同步。但是这时主节点突然断电然后重新选举一个从节点为主节点,这个从节点只有1,2,3的信息,又继续处理请求变成了[1, 2, 3, 7, 8, 9]。这时主节点重启完成,想要加入到集群,但是它的状态不对,它太超前了。它要怎么回退到之前的状态3呢?这得先说说mongo中的oplog。oplog是幂等的,比如x原本为1,写操作{x: {$inc: 1}}将产生的oplog却是{x: {$set: 2}},这样即使oplog重复读取2次,x的值也仍是正确的。所以这就使得恢复的主节点无法根据oplog做4、5、6的补偿操作回滚,之前的数据已经被覆盖。Mongodb的做法是每隔一段时间将所有数据备份(文件复制操作),叫做checkpoint。通过timestamp,恢复的主节点通过找到3之前最近的checkpoint,比如说2,回滚到那个状态再逐个读取3, 7, 8, 9从而和集群的其他节点保持一致。
2. Global logic clock 提供了causal consistency和global snapshot isolation。前面提到物理时钟不可靠的,即使t1在数值上小于t2,但也不能说t1发生在t2之前,因为t1与t2值并不准确。但还是有一个简单的方法可以生成causality sequence number,即Lamport timestamp。
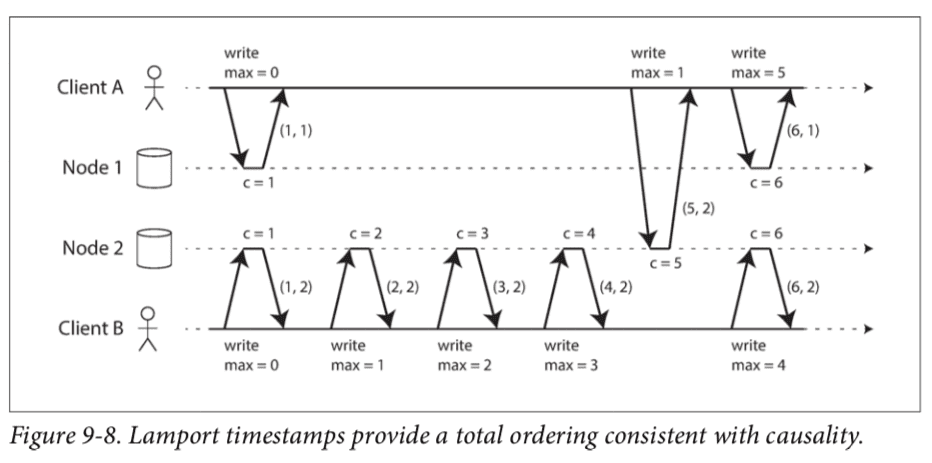
Lamport timestamp由(counter, node ID)组成(node ID表示Mongodb的一组shard),判断大小时先比较counter再比较node ID,不会存在counter和timestamp都相同的情况。每个node记录当前节点最大请求数(写请求),当它收到请求或者返回含有一个更大的counter值时,立马将自身counter更新到那个值。上图中,A先从node 2中收到counter=5,然后它在写请求里带上counter=5发送给node 1。当node 1接收后它马上将自身的counter更新到5,再依操作加1变成6。从每个节点各自看来,counter大的一定后发生。有依赖关系的2个操作,其lamport timestamp总是增加的。
Global logic clock能够帮助实现global snapshot isolation。每个读请求都带上客户端当前的“timestamp”,每个shard则根据MVCC返回在此timestamp时刻应该看到的数据,即在此时往前最近的写入操作为准。即使在2个相同的读操作间隔中数据被其他客户端修改了,通过在读请求中带上timestamp也能得到一致的数据。原理虽然复杂但API接口确很简单
let session = db.getMongo().startSession({causalConsistency: true})
db = session.getDatabase(db.getName())3. Safe secondary reads 有了global logic clock便可以从从节点读数据。设想一个典型的场景,用户修改了资料刷新网页后希望看到修改后的数据。通用做法是从主节点写从主节点读,但会增加主节点的压力。虽然写操作必须在主节点中执行,但读操作希望能分担到从节点,否则有点浪费从节点的资源。但如果从从节点中读,客户端写操作从主节点返回后立刻去请求从节点,从节点并不保证一定能返回最新数据。当然Mongodb可以通过设置write concern确保数据已经从主节点复制到从节点后再返回写操作,但是这样又会导致写操作的执行时间变长。而有了global logic clock,就可以在读从节点的读请求带上主节点写请求的返回的时间x,从节点的oplog如果已经处理到x,那就可以直接返回,否则等待oplog处理到x之后再读取数据返回给客户端。

4. Logical session 带来2个好处。1) 在3.4中如果shell挂了,或者mongos挂了,正执行中的operation, cursor就永远丢失。虽然Mongodb通过timeout可以清除这些cursor但用户基本上是无法干预的。但是在3.6中,引入了logical session(server session),operation和cursor会记录logical session id(lsid),当shell恢复或切换mongos后可以根据lsid杀死之前相关的cursor。2) Mongodb维护一个session collection,每个操作都会更新session最后更新时间,如果session长时间没有任何操作(比如说5分钟),Mongodb就可以回收这个session。这样在执行某些事务时,如果客户端没有提交,可以及时回滚清除这些状态。
5. Retrable write 允许客户端重新提交事务。假如客户端执行多个写操作时因网络中断或选举导致事务提交失败,客户端虽然没法区分究竟哪条写操作失败,但它可以重头提交所有写操作,Mongodb保证即使重复提交,所有写操作满足exactly-once, all-or-nothing。重新提交的写操作会在oplog中产生重复的entry,Mongodb通过比较这些entry,相同的写操作就会被跳过。前面说到oplog entry基本上都是幂等的,所以这种比较是有效的。但有一类操作例外:find-and-modify,这种操作修改的数据取决collection那时的状态,没法仅根据oplog entry确定具体修改了什么。针对这种情况,Mongodb记录下这个collection的preimage和postimage,即修改前和修改后的数据快照。通过比较这2个快照就可以判断出操作是否相同。
总结来说,Mongodb在3.6中实现了一些事务所必须但对非事务操作也有益的特性。这些特性/功能彼此之间相互关联,是实现事务的必要条件。上述实现原理的介绍,一般开发者并不需要特别清楚,我也只是简单扯扯,不影响日常使用。在我略微了解了这些实现原理之后,还是对Mongodb 4将发布的多文档事务抱有信心和期待。Mongodb非常适合GraphQL,两者结合将大大提高开发效率。但是在4.0发布之前(现在)我并不很支持在生产环境中使用Mongodb,除非你不需要事务。请看这个吐槽:Mongo DB is Web Scale,以及Reads may miss matching documents that are updated during the course of the read operation。听到4.0的发布消息,reddit上也是诟病缺乏事务的居多:Friends don’t let friends use Mongodb。
历史往往是相似的,关系型数据库早期其实也不支持事务,NoSQL为了高扩展性而放弃事务最终仍要重新拾起,重走之前关系型数据库的老路,因为用户需要事务。但这并非回退,而是新的挑战。